Python的中文字符处理
都说python对中文不太友好。
我们看看下面两个例子:
测试环境是ubuntu;
python版本为2.7
》a = '呵呵'
》a
》'\xe5\x91\xb5\xe5\x91\xb5'
》print a
》呵呵
为什么print 和 直接输入变量回车显示的东西不一样呢?
\xe5\x91\xb5\xe5\x91\xb5这些是什么东西啊。一定很奇怪。其实bytes字符编码,是8进制的东西。
Spark,搞大数据的人都应该用过吧。spark作为主流的大数据处理框架,到底为什么这么多人用呢?我们少扯淡,直接动手写大数据界的HelloWorld:WordCount。
先贴上代码(Scala版本):
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("WorkCount")
val sc = new SparkContext(conf)
val file = "hdfs://127.0.0.1:9000/file.txt"
val lines = sc.textFile(file)
val words = lines.flatMap(_.split("\\s+"))
val wordCount = words.countByValue()
println(wordCount)
}
短短10多行代码,就已经完成了,比大家想象的要简单,完全看不出Spark背后做了什么处理。分布式,容错处理,这就是Spark给我们带来的福利。
在SparkStreaming中,数据中的每个batch都是只有一个RDD,为什么我们还要用ForeachRDD 在每一个RDD呢? 不是只有一个RDD吗?
Dstream也就是离散stream,就是把连续的数据分成一小团一小团。我们用专业术语“microbatching”来描述。每个microbatch 变成一个RDD以便Spark的后续处理。在每一个batch interval中,每个DStream有且仅有一个RDD。
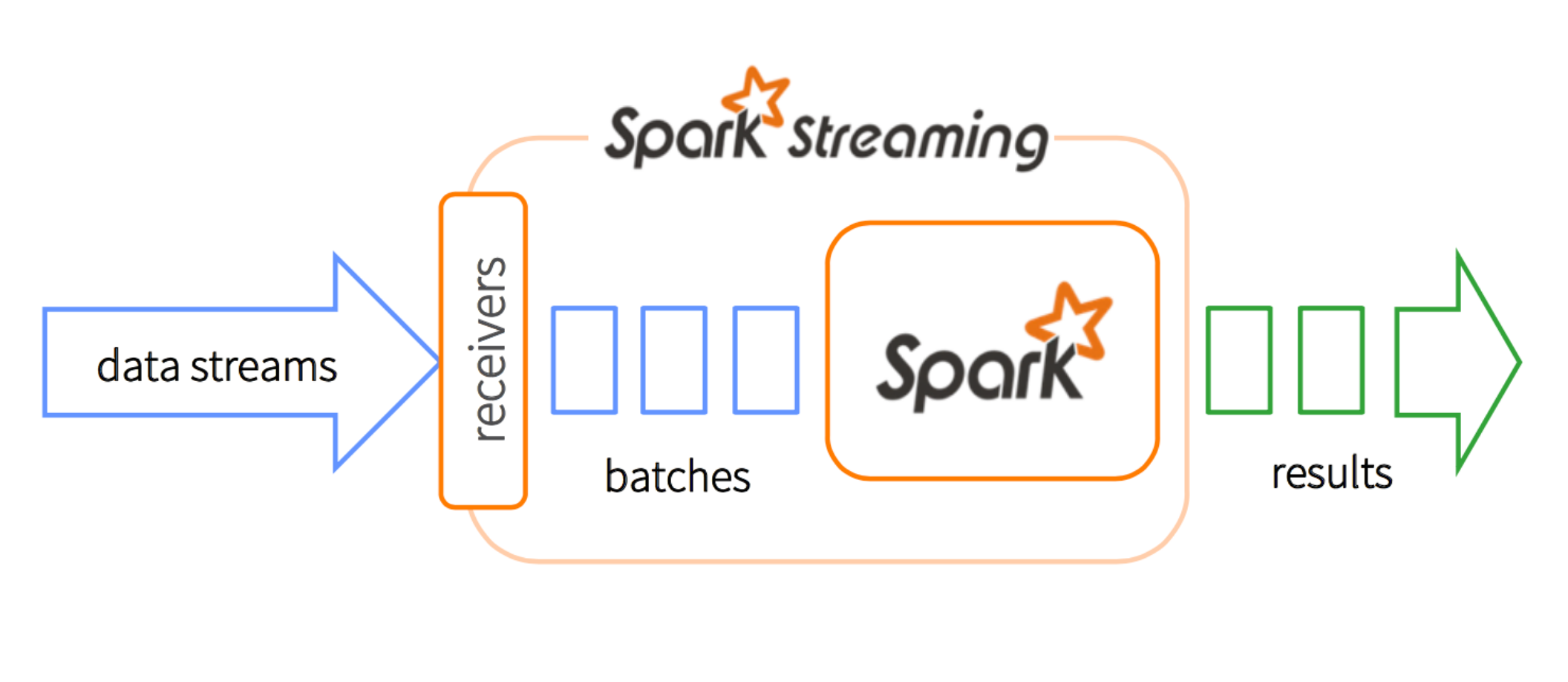
然而RDD是什么呢,RDD是一个分布式数据集合。你可以认为它是一个告诉你实际数据在集群中具体什么地方的指南者(pointer)。
原文在 http://www.aaronsw.com/weblog/productivity
有人跟我说:“你花在看电视上的时间足够用来写本书了。”毫无疑问,把时间花在写书上花在看电视上更好。但这里隐含了一个假设,即时间是“可互换的”。也就是说,看电视的时间可以轻松地用来写书。但悲催的是事实并非如此。
不同的时间有不同的质量等级。如果我正走向地铁站而且忘带笔记本了,我就很难写什么文章。同样,如果你不停地被打断,也很难集中注意力。另外还有些心理和情感上的因素:有时候我心情不错,就愿意去主动做一些事;也有些时候我心情郁闷,就只能看看电视了。
如果你想变的更加有效,你必须意识到这个事实,并很好的处理它。首先,你得利用好不同类型的时间。其次,你得提高时间的质量。
1.1 选择好问题