通俗理解Spark Streaming Dstream 的ForeachRDD
在SparkStreaming中,数据中的每个batch都是只有一个RDD,为什么我们还要用ForeachRDD 在每一个RDD呢? 不是只有一个RDD吗?
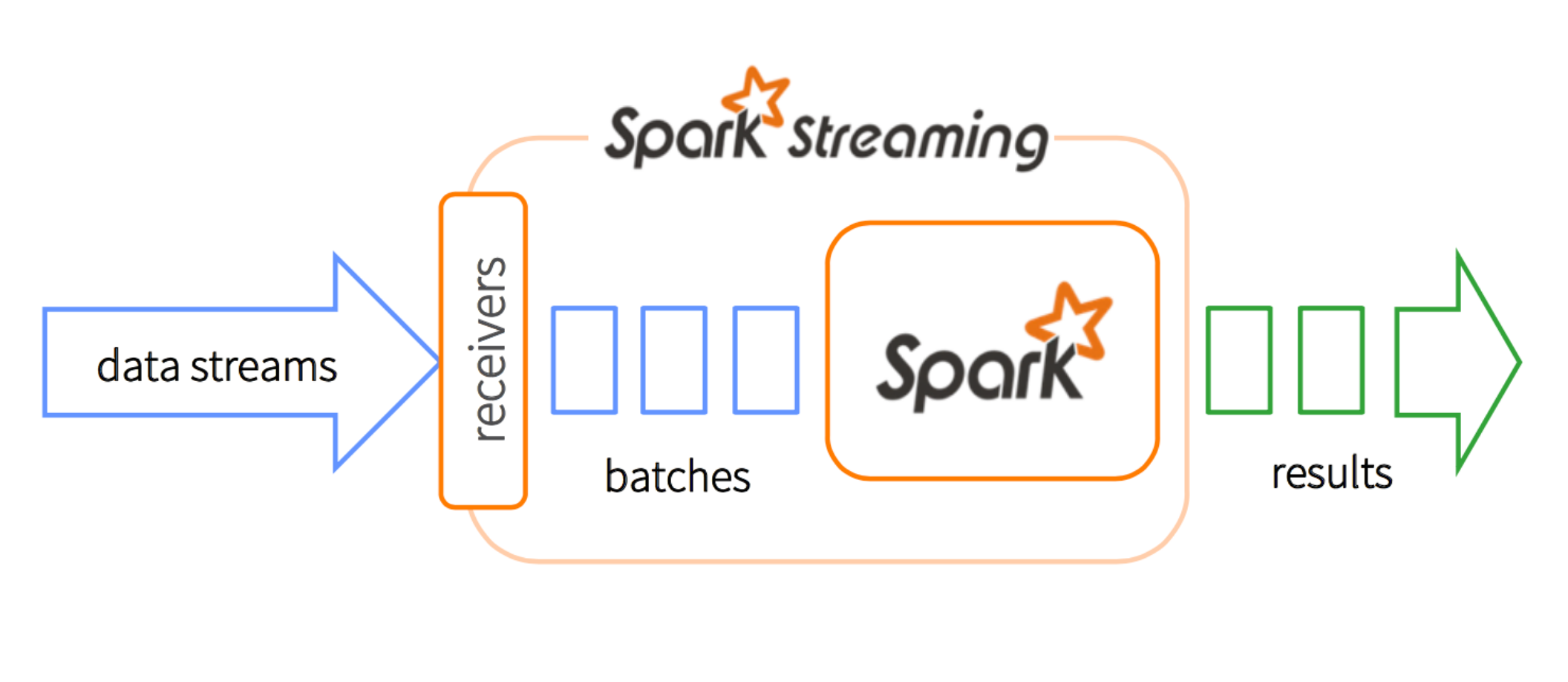
Dstream也就是离散stream,就是把连续的数据分成一小团一小团。我们用专业术语“microbatching”来描述。每个microbatch 变成一个RDD以便Spark的后续处理。在每一个batch interval中,每个DStream有且仅有一个RDD。
然而RDD是什么呢,RDD是一个分布式数据集合。你可以认为它是一个告诉你实际数据在集群中具体什么地方的指南者(pointer)。
Dstream.foreachRDD在SparkStreaming中是一个“output operator”,它让你直接基于Dstream的RDDs去处理数据。比如说,用foreachRDD方法将数据写入数据库
这里有个容易疑惑的地方,DStream是和时间有关的集合。我们来对比一下传统的集合。我们用一群客户(users)来举个例子:
val userDStream:DStream[User]=???
userDStream.foreachRDD{usersRDD =>
usersRDD.foreach{user => serveCoffee(user)}
}
注意:
- DStream.foreachRDD返回给你的是RDD[user],不是单单一个user。回到上面咖啡的这个例子,这个客户集合 是指某个时间区间(比如下午一点到两点)的集合
- 为了处理单个集合的元素,需要进一步操作(operate) RDD。在这个案例中,我们用RDD.foreach来对每个客户serve coffee