通过这个图表中了解下map-reduce流程。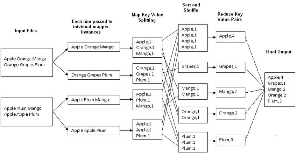
我们将讨论Hadoop中的word-count问题,hadoop在Hadoop中也称为hello world。
word-count是一个程序,我们从文件中查找每个字的出现。
让我们尝试了解MR过程:
Step1
输入文件:我们需要一些数据来运行字计数程序,以便在群集上运行该程序,
第一步应该是将该文件放在Hadoop上,这可以通过多种方式完成,
最简单的方法是使用hadoop shell命令:可以使用put或copyFromLocal这样的命令:
Step2
Map Reduce以键值对的形式进行交互,这意味着mapper将以键值对的形式获取输入,他们将进行所需的处理,然后以键值对的形式产生中间结果,
该结果将被输入reducer对此进行进一步的工作,最后reducer还将其输出写入键值对中。
但是我们知道mapper仅在主驱动程序之后执行,因此谁以键值对的形式向mapper提供输入呢?input format就是干这个的。
InputFormat是执行两个主要操作的类:
1)输入分割(此输入input split的mapper实例数或输入input split的mapper数,
默认情况下,如果采用默认配置,则一个split大小等于一个block,但是你可以更改split大小根据你的需要。
因此,如果你正在处理512 mb的数据并且块大小为64 mb,则将使用8个输入split size,8个mapper实例将运行或8个mapper。
2)在键值对中破坏数据(记录读取器是在后端执行此操作的类)
现在,mapper的键和值将由你使用的文件输入格式来驱动,
例如TextInputFormat,这是最常用的输入格式。它发送longWritable(等效于long)作为键,并将Text(string)作为值发送给mapper
你的mapper类将在1个split上工作,在该类中,你具有一个map函数,该函数一次只能在一行上工作,因此如上图所示,单行将进入map函数
例如,它发送:“ Apple orange Mango”到地图功能
3)在mapper中,我们将line作为输入,因此现在我们需要编写逻辑。
我们将行根据分隔符分成单词,因此现在我们在一行中有一个单词。我们知道map在键值对上工作。 我们可以将这项工作作为关键,并将值设为1
为什么我们把单词作为关键而不是反过来,因为下一阶段是
shuffle和排序阶段:在此阶段,框架将基于相似的键组成组,或者在shuffle阶段将所有不同的键放在一起,并根据键对它们进行排序。
- 现在,我们再次修改:
最初我们有一个文件,该文件根据输入拆分发送到不同的不同的mapper,然后在map函数的mapper类中,我们以一行作为输入,
因此针对一行构建了逻辑,对于一个实例,所有行将以相似的方式工作,最后所有实例都可以像这样并行工作。
现在,假设你正在运行10个mapper,现在在map reduce中,reducer的数量始终少于mapper。
因此,如果我们使用10个mapper,则最有可能使用2-3个reducers。
shuffle和排序阶段,我们已经看到所有类似的键将组合在一起。
首先,将基于一定的原则来决定将某个mapper数据传递给某个reducer。在万一情况下,必须将10个mapper数据分给2个reducer,因此可以根据该数据进行决策。
有一个叫做Partitioner的组件,该组件将基于哈希分区并在其上使用模运算符(比如 %)来决定将某个mapper输出输出到某个reducer。
因此,如果我们使用hash,则可以100%确保所有相同的键都分配给相同的reducer。
我们不必为任何事情而烦恼,因为框架已被设计成可以有效地做到这一点,但是是的,因为它是用Java编写的,
所以我们可以根据需要自定义键,自定义partitioner,定制comparator等等。
4)Reducer:Reducer现在将在其输入中获取键和其值的列表,如下所示
Apple,<1,1,1,1>
现在在reducer中我们编写逻辑我们到底想做什么,对于我们的情况,我们要进行word-count,因此简单地我们必须计算值。
这也是我们在Map阶段最初将1作为值的原因,因为我们只需要计数。
输出:最终输出将由reducer再次以键值对的形式写入HDFS。