为什么什么买这本书
最近想为Spark社区做点贡献吧,又不知道从何下手,就想先买本Spark原理的书来研究下先。
于是在淘宝上花了90多买了这本 《Spark内核设计的艺术架构设计与实现》
Akka 到 Netty
了解到Spark1.x使用了Akka做内部的通信架构。比如Spark各个组件之间的通信,用户文件与Jar包的上传,
节点之间的shuffle过程,Block数据的复制与备份等等。
然而,在Spark2.0 Akka被移除,而是写了自己基于Netty的RPC框架。
那么Netty为什么可以取代Akka?
首先不容置疑的是Akka可以做到的,Netty也可以做到,但是Netty可以做到,Akka却无法做到,原因是啥?
在软件栈中,Akka相比Netty要Higher一点,它专门针对RPC做了很多事情,而Netty相比更加基础一点,可以为不同的应用层通信协议(RPC,FTP,HTTP等)提供支持,
在早期的Akka版本,底层的NIO通信就是用的Netty;其次一个优雅的工程师是不会允许一个系统中容纳两套通信框架,恶心!
最后,虽然Netty没有Akka协程级的性能优势,但是Netty内部高效的Reactor线程模型,无锁化的串行设计,
高效的序列化,零拷贝,内存池等特性也保证了Netty不会存在性能问题。
TransportClient
有了TransportClientFactory,Spark的各个模块就可以使用它创建RPC客户端TransportClient了。
每个TransportClient实例只能和一个远端的RPC服务通信,所以Spark中的
组件如果想要和多个RPC服务通信,就需要持有多个TransportClient实例。
Metrics
了解到了软件开发有个度量系统这么个东西,哈哈长见识了。Spark的度量系统是用的Metrics(https://github.com/dropwizard/metrics)
SparkContext
SparkContext 是Spark中的元老级API,从0.x.x版本就已经存在了。SparkContext相当于Spark应用程序的
发动机引擎,而SparkContext的参数则有SparkConf负责,SparkConf就是操作面板。
第五章Spark的执行环境
前几篇幅,主要讲了Spark的RPC,这玩意的作用比如说:从worker是怎么从Driver端去下载jar包之类的依赖文件。
看了十几页,完全没有头绪,细节代码也看不懂。总结一下:对于看不懂的篇章,并且不是很感兴趣的内容还是跳过吧。
不要在上面耗费太多的时间。我觉得看这种书还是要提前看看目录了解下再看内容,不要一章一章地阅读全书。
另外,这里我想说说看书的状态。看书要在一个好的状态下才能有效率地阅读。我认为好的状态有两个方面:一个是
外界环境,另一个是自己的身心状态。
外界状态有这么几个方面吧:安静程度,受打扰程度,氛围环境等等。所以通常我在图书馆里面的阅读效率是比较高的。
身心状态有:身体状况,心情状态等等。比如最近几天我的坐骨神经就很不舒服,非常很勉强地去看书,效率非常低。
还是要先把身体状态调整好再去阅读吧。
第六章 Spark Block
文件系统的文件在存储到磁盘上时,都是以块为单位写入的。操作系统的块是以固定的大小读写的,例如:512字节、
1024字节、2048字节等。
在Spark的存储体系中,数据的读写也是以块为单位,只不过这个块并非操作系统的块,而是涉及用于Spark存储体系的块。
每个Block都有唯一的标识,Spark把这个标识抽象为BlockId。
Spark与Hadoop的重要区别之一就是对于内存的使用。Hadoop只讲内存作为计算资源,Spark除将内存作为计算资源外,
还将内存的一部分纳入到存储体系中。Spark使用MemoryManager对存储体系和内存计算所使用的内存进行管理。
StorageMemoryPool是存储体系用到的内存池,ExecutionMemoryPool是计算引擎用到的内存池
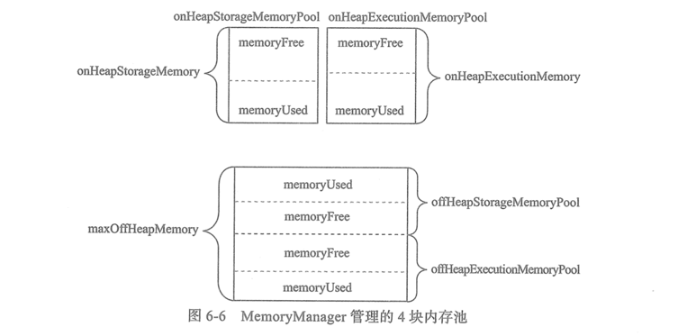
MemoryStore负责将Block存储到内存。Spark通过将广播数据、RDD、Shuffle数据存储到内存,减少了对磁盘IO
的依赖,提高了程序的读写效率。
第七章 调度系统
Scheduler 分为DAGScheduler 和 TaskScheduler
容错处理:当某个worker节点上的Task失败时,可以利用DAG重新调度计算这些失败的Task(执行已成功的Task可以从CheckPoint中读取
,而不用重新计算)。在流失计算的场景中,Spark需要记录日志和CheckPoint,以便利用CheckPoint和日志对数据恢复。
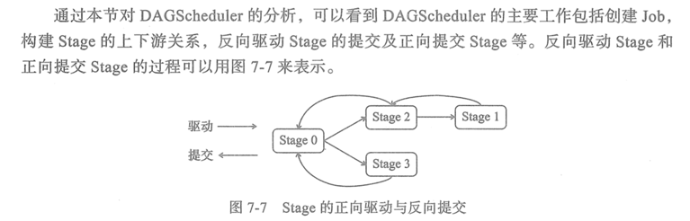
Spark中的Job可能包含一个到多个Stage,这些Stage的划分是从ResultStage开始,从后往前边划分边创建的。(执行的时候应该不是)
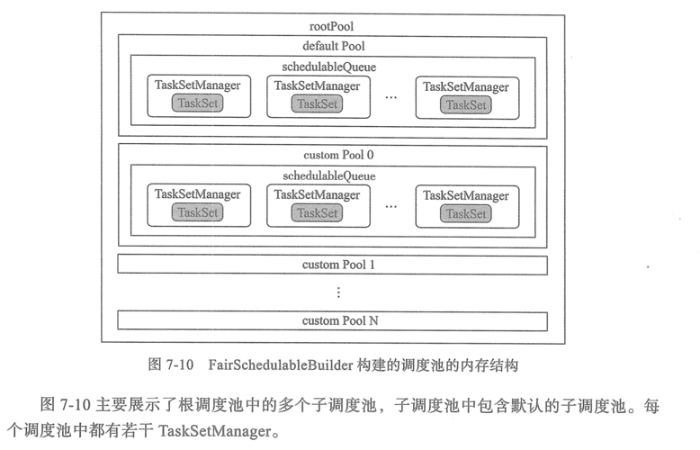
调度池对TaskSet的调度取决于调度算法,有两种可选的算法:FIFO;
Spark的调度池中的调度队列与YARN中调度队列的设计非常相似,也采用了层级队列的管理方式。
我看了一下官网的文档:
想法20200130
要看懂Spark的源码,设计模式得比较熟练呀。里面的这些类是怎么依赖的,是怎么设计的,我完全不懂,这是一拍脑袋决定的呢?还是有
这种设计相关的设计模式套路。所以,我觉得设计模式应该要掌握好才能让读代码更有意义。
Spark的资源调度分为两层:
第一层是Cluster Manager(Yarn模式下是RM,Standalone模式为Master)将资源分配给Application
第二层是Application进一步将资源分配给Application的各个Task。
ExecutorLossReason 有四个子类,分别代表四种不同的原因:
SlaveLost:Worker丢失
LossReasonPending:位置的原因导致的Executor退出。
ExecutorKilled:Executor被杀死了。
ExecutorExited:Executor退出了。
OutputCommitCoordinator 是DAGScheduler中的重要组件,其实现方式简洁明了,有很高的借鉴意义。
TaskScheduler依赖于LaucherBackend和SchedulerBackend。通过对TaskSchedulerImpl的初始化、
启动、提交Task、资源分配等功能的分析,更深入地了解TaskSchedulerImpl的调度流程。
第八章计算引擎
Tungsten最早是由Databricks公司提出的对Spark的内存和CPU使用进行优化的计划。Tungsten使用
sun.misc.Unsafe的API直接操作系统内存。
在Tungsten中实现了一种与操作系统的内存Page非常相似的数据结构,这个对象就是MemoryBlock。
Task的定义:
Task主要包括ShuffleMapTask和ResultTask两种。每次任务尝试都会申请单独的连续内存,以执行计算。
Task中提供的抽象方法如下:
- runTask: 运行Task的接口
- preferredLocations:获取当前Task编好的位置信息。
ShuffleMapTask类似于Hadoop中的MapTask,它对输入数据计算后,将输出的数据在Shuffle之前映射到
不同的分区,那么下游处理各个分区的Task将知道处理哪些数据。
ResultTask类似于Hadoop中的ResultTask,它读取上游ShuffleMapTask输出的数据并计算得到最终的结果。
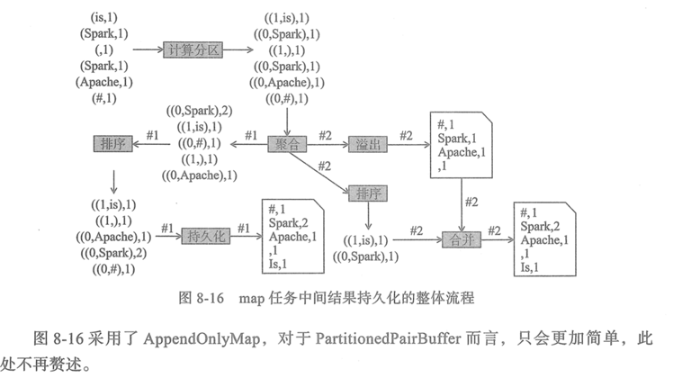
AppendOnlyMap
Spark 提供了AppendOnlyMap来对null值进行缓存。AppendOnlyMap还是在内存中对任务执行结果进行聚合运算的利器。
AppendOnlyMap内置排序使用的TimSort,也就是优化版的归并排序。
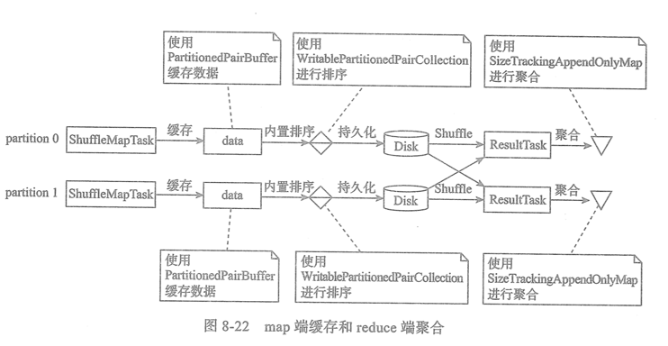
本章小结
为了提升程序执行效率,Spark有时需要在map端对数据进行缓存、聚合、内置排序等操作。reduce端为了提升
效率,也可能需要对数据进行缓存、聚合、排序。
Shuffle过程中,map任务通过将多个分区的数据写入同一个文件,减轻了读写大量小文件给磁盘IO效率带来的压力。
reduce任务通过对存储在同一个远端节点上的Shuffle Block进行积累,批量下载远端的Block,节省了网络IO。
想法20200203
学习的本质是社交。
最近几天一个人在家看这本书,感觉非常枯燥乏味,很难坚持下去。我认为最好还是能加入
一个社区和其他志同道合的人一同分享并学习。或者想办法靠近比你厉害的人。
但是,要找到这样的环境很难!
第九章部署环境
Driver:应用驱动程序,有了Driver,Application才会被提交到Spark集群运行。Driver可以选择在客户端运行,
也可以选择项Master注册,然后由Master命令Worker启动Driver。
Master:Spark的主控节点。在实际的生产环境中会有多个Master,只有一个Master处于active状态,
其余的Master处于slave状态
Worker:Spark的工作节点,向Master汇报自身的资源、Executor执行状态的改变,并接受Master的命令
启动Executor或Driver。
HeartbeatReceiver
HeartbeatReceiver 运行在Driver上,用以接收各个Executor的心跳(HeartBeat)消息,对各个Executor
的”生死”进行监控。
Master 详解
Master负责对整个集群中所有的资源的统一管理和分配,它接收各个Worker的注册、更新状态、心跳等信息,也接收Driver
和Application的注册。
Worker向Master注册时会携带自身的身份和资源信息(ID、host、port、内核数、内存大小等),这些资源
将按照一定的资源调度策略分配给Driver或Application。Master给Driver分配了资源后,
将向Worker发送启动Driver的命令。
Master给Application分配了资源后,将向Worker发送启动Executor的命令,后者在接收到启动Executor的
命令后启动Executor。
启动Master有作为JVM进程内的对象启动和作为单独的进程启动的两种方式。