背景
最近有个需求是这样子的,某个task要求一定要一个一个地执行,不能并发执行。
比较简单的办法是直接将 celery worker启动为 一个进程: “-c 1”。 但是,这种方法会导致其它的task也只能单进程了。
后来通过Google,查找了很多例子,最普遍的一个做法是参考官方文档的做法, 代码如下:
|
|
但是,上面的逻辑只是在有task正执行的时候忽略了新增task。比如说有个import_feed task 正在运行,还没有运行完,
再调用apply_async的时候就会不做任何操作。
所以得在上面代码的基础上改一改。
实践
这里我用了一个上厕所的例子。假设有一个公共厕所。如果有人在用着这个厕所的时候其他人就不能使用了,得在旁边排队等候。
一次只能进去一个人。废话少说直接上代码:
|
|
上面代码是主要的task处理所及。另外,要先重写一下Task类的 after_return 方法,使得当没能执行的task(在门口排队的人)
在正在执行task(正在用厕所的人)成功执行完后,接着执行下一个task(下个人接着用厕所)。
完整代码如下:
|
|
测试
可以新建一个test_celery项目来检验一下。新建一个目录名叫 test_celery
然后新建一个tasks.py文件,内容就是上面代码。
用下面命令来启动Celery worker,这里用了8个进程来处理。设置多点可以增加task的并行执行任务数。
然后,可以启动ipython 进行调用task。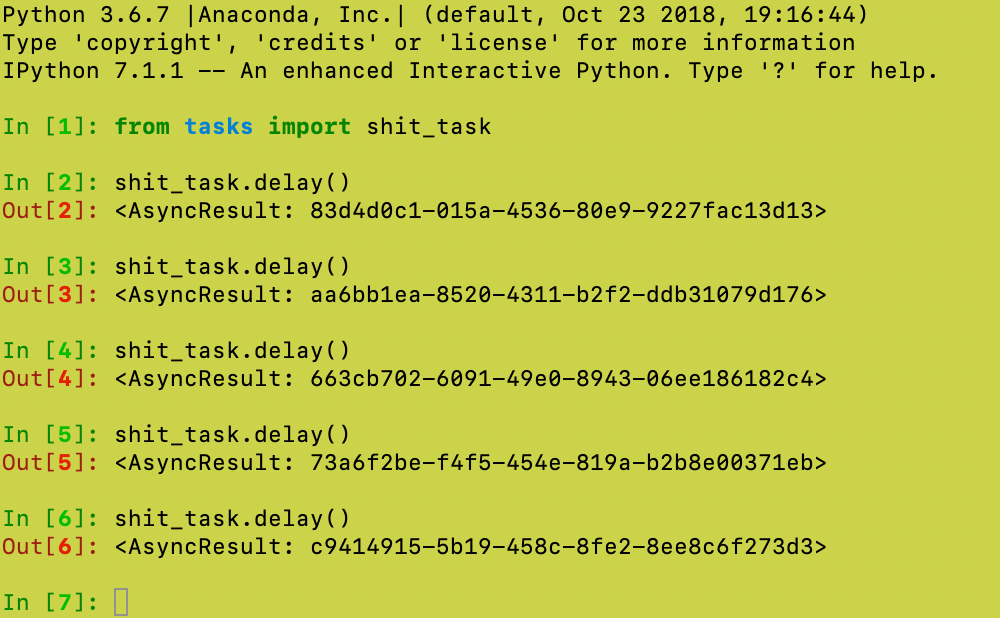
快速地敲几个task.delay
在celery日志中我们可以看到两个shit_tasks 是一个接一个来运行的。而不是并行执行。
代码放在了:
https://github.com/mikolaje/celery_toys/tree/master/test_lock