前言:最近在知乎上看到很多Python职位的面试都会问Python的数据结构。很多大公司,比如知乎,在面试python的工程师的时候都会很注重基础;
比如会问:python内置的list dict set等使用和原理。collections 模块里的deque,Counter,OrderDict等。 常用的排序算法和时间复杂度。
今天我就简单说说我学到的关于Python Dict 的见闻。
于是,首先我查看到《流畅的python》一书的第3章。
- 首先我们看看Python是如何用散列表来实现dict类型。
什么是散列表:
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。
在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两
个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
散列算法:
1.为了获取 my_dict[search_key] 背后的值,Python 首先会调用hash(search_key) 来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量(貌似是hash(key) 和 数组的长度-1 作 与运算,hash(key)& (size-1),在散列表里查找表元(具体取几位,得看当前散列表的大小)。
2.若找到的表元是空的,则抛出 KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。
3.这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。
4.如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。
5.Python 解决散列冲突的方法用的是开放地址法。
如下图所示: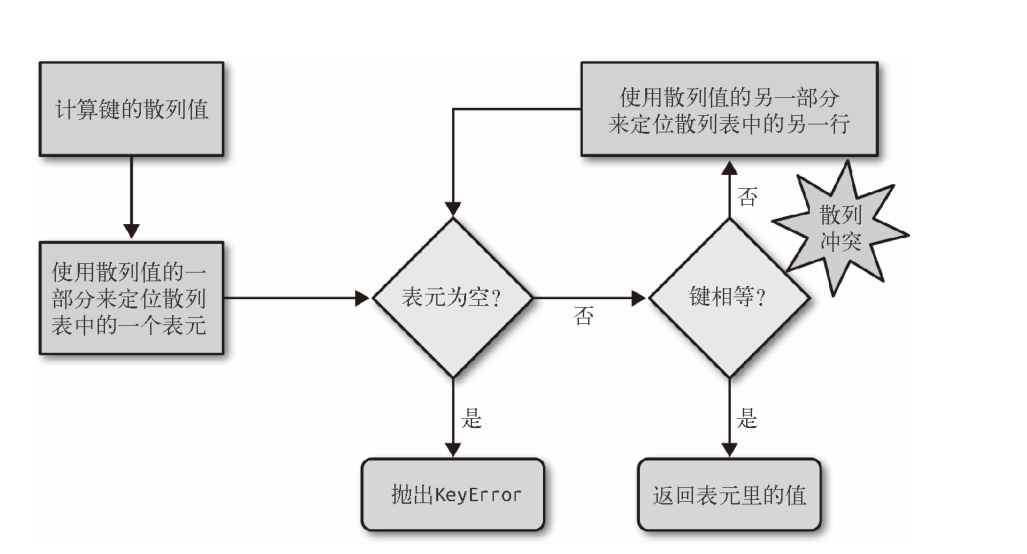
Python dict的特性:
1.字典在内存上的开销巨大。
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。
2.键查询很快。
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里。
3.往字典里添加新键可能会改变已有键的顺序。
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。
关于Python的开放地制法解决hash冲突的实现可以参考下
https://harveyqing.gitbooks.io/python-read-and-write/content/python_advance/python_dict_implementation.html
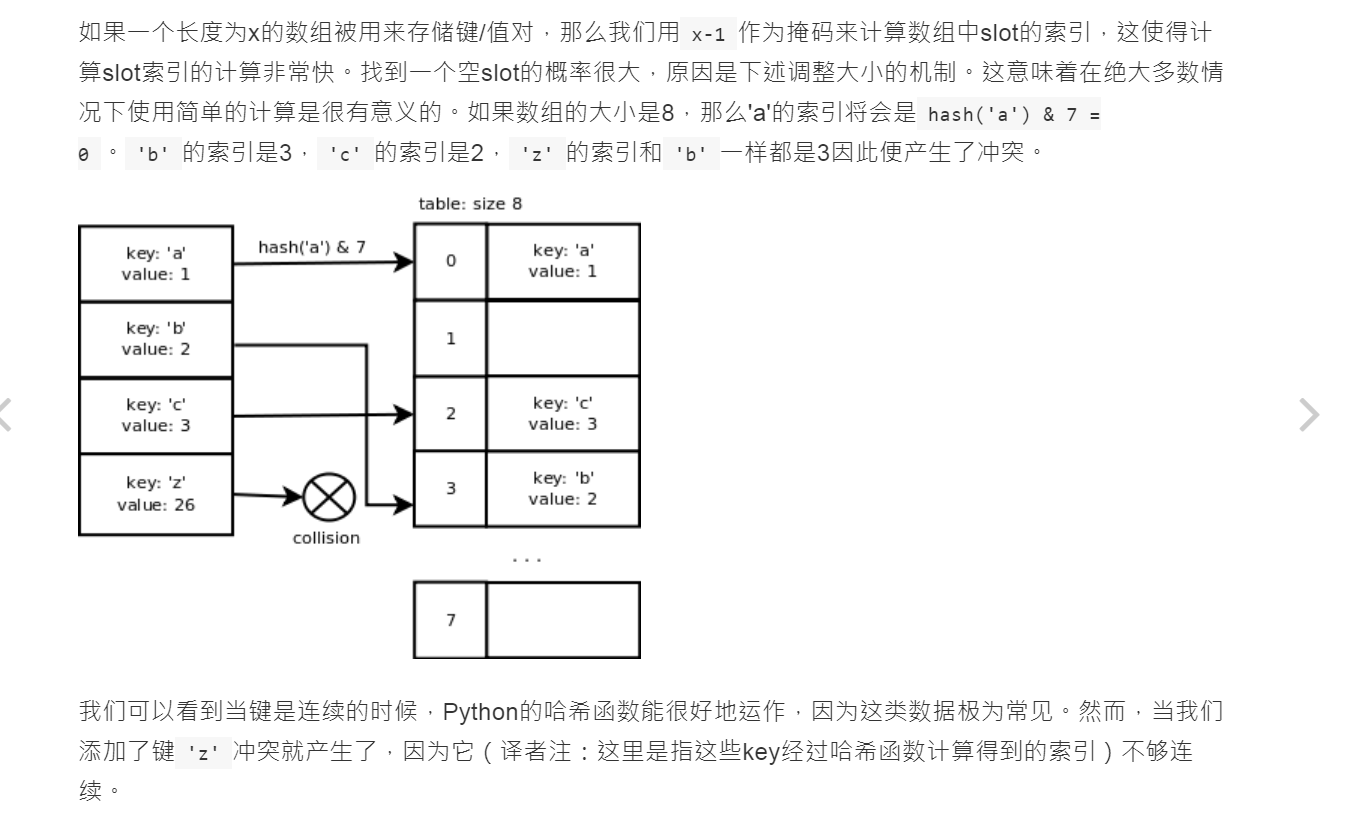
若要了解详细的内部机制,推荐阅读
http://python.jobbole.com/85040/