什么是Apache Calcite ?
Apache Calcite 是一款开源SQL解析工具, 可以将各种SQL语句解析成抽象语法术AST(Abstract Syntax Tree),
之后通过操作AST就可以把SQL中所要表达的算法与关系体现在具体代码之中。
Calcite的生前为Optiq(也为Farrago), 为Java语言编写, 通过十多年的发展, 在2013年成为Apache旗下顶级项目,并还在持续发展中。
该项目的创始人为Julian Hyde, 其拥有多年的SQL引擎开发经验, 目前在Hortonworks工作, 主要负责Calcite项目的开发与维护。
目前, 使用Calcite作为SQL解析与处理引擎有Hive、Drill、Flink、Phoenix和Storm。
可以肯定的是还会有越来越多的数据处理引擎采用Calcite作为SQL解析工具。
Calcite 主要功能
总结来说Calcite有以下主要功能:
- SQL 解析
- SQL 校验
- 查询优化
- SQL 生成器
- 数据连接
3. Calcite 解析SQl的步骤
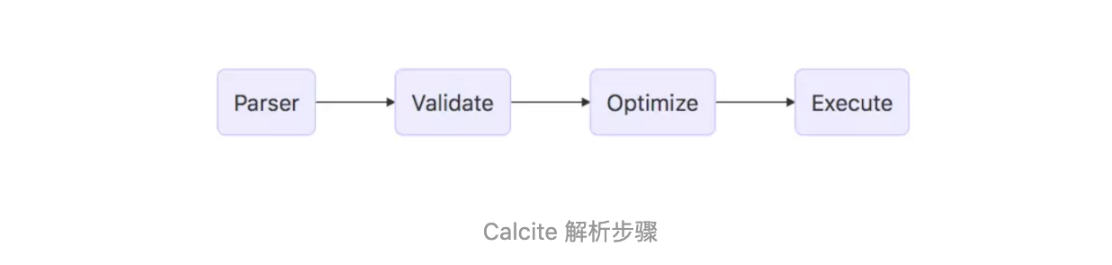
如上图中所述,一般来说Calcite解析SQL有以下几步:
|
|
Calcite相关组件
Calcite主要有以下概念:
Catelog: 主要定义SQL语义相关的元数据与命名空间。
SQL parser: 主要是把SQL转化成AST.
SQL validator: 通过Catalog来校证AST.
Query optimizer: 将AST转化成物理执行计划、优化物理执行计划.
SQL generator: 反向将物理执行计划转化成SQL语句.
category
Catalog:主要定义被SQL访问的命名空间,主要包括以下几点:
schema: 主要定义schema与表的集合,schame 并不是强制一定需要的,比如说有两张同名的表T1, T2,就需要schema要区分这两张表,如A.T1, B.T1
表:对应关系数据库的表,代表一类数据,在calcite中由RelDataType定义
RelDataType 代表表的数据定义,如表的数据列名称、类型等。
一句Sql
id, name则为data type field
bigint为 data type
A 为schema
INFO 为表
SQL Parser
由Java CC编写,将SQL转化成AST.
Java CC 指的是Java Compiler Compiler, 可以将一种特定域相关的语言转化成Java语言
在Calcite中将标记(Token)表示为 SqlNode, 并且Sqlnode可以通过unparse方法反向转化成SQL
cast(id as float)
Java CC 可表示为
e = Expression(ExprContext.ACCEPT_SUBQUERY)
dt = DataType() {agrs.add(dt);}
….
Query Optimizer
首先看一下
通过Calcite转化为:
是未经优化的RelNode树,可以发现最底层是TableScan,也是读取表的原始数据,紧接着是LogicalJoin,Joiner的类型为INNER JOIN, LogicalJoin之后接下做LogicalFilter 操作,对应SQL中的WHERE条件,最后做Project也就是投影操作。
但是我们可以观察到对于INNER JOIN而言, WHERE 条件是可以下推,如
这样可以减少JOIN的数据量,提高SQL效率
实际过程中可以将JOIN 的中条件下推以较少Join的数据量
这个条件可以先下推过滤s1中的数据, 但在特定场景下,有些不能下推,如下sql:
如果s1,s2是流式表(动态表,请参考Flink流式概念)的话,就不能下推,因为s1下推的话,由于过滤后没有数据驱动join操作,因而得不到想要的结果(详见Flink/Sparking-Streaming)
那接下来我们可能有一个疑问,在什么情况下可以做类似下推、上推操作,又是根据什么原则进行的呢?如下图所示
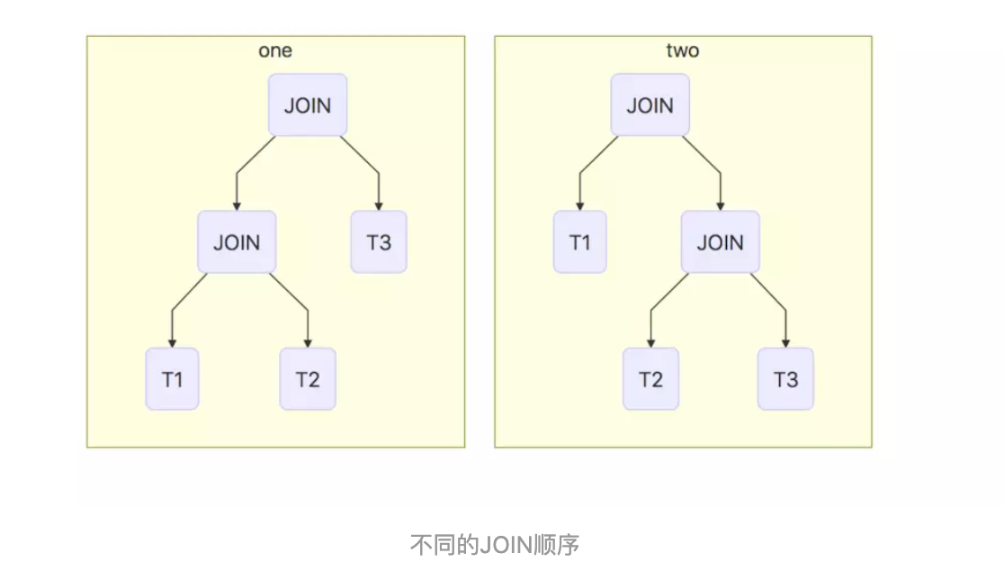
类似于此种情况JOIN的顺序是上图的前者还是后者?这就涉及到Optimizer所使用的方法,Optimizer主要目的就是减小SQL所处理的数据量、减少所消耗的资源并最大程度提高SQL执行效率如:剪掉无用的列、合并投影、子查询转化成JOIN、JOIN重排序、下推投影、下推过滤等。目前主要有两类优化方法:基于语法(RBO)与基于代价(CBO)的优化
RBO(Rule Based Optimization)
通俗一点的话就是事先定义一系列的规则,然后根据这些规则来优化执行计划。
如
ProjectFilterRule
此Rule的使用场景为Filter在Project之上,可以将Filter下推。假如某一个RelNode树
则可优化成
此Rule的使用场景为Filter在Join之上,可以先做Filter然后再做Join, 以减少Join的数量
等等,还有很多类似的规则。但RBO一定程度上是经验试的优化方法,无法有一个公式上的判断哪种优化更优。 在Calcite中实现方法为 HepPlanner
CBO(Cost Based Optimization)
通俗一点的说法是:通过某种算法计算SQL所有可能的执行计划的“代价”,选择某一个代价较低的执行计划,如上文中三张表作JOIN, 一般来说RBO无法判断哪种执行计划优化更好,只有分别计算每一种JOIN方法的代价。
Calcite会将每一种操作(如LogicaJoin、LocialFilter、 LogicalProject、LogicalScan) 结合实际的Schema转化成具体的代价数,比较不同的执行计划所具有的代价,然后选择相对小计划作为最终的结果,之所以说相对小,这是因为如果要完全遍历计算所有可能的代价可能得不偿失,花费更多的人力与资源,因此只是说选择相对最优的执行计划。CBO目的是“避免使用最差的执行计划,而不是找到最好的”
目前Calcite中就是采用CBO进行优化,实现方法为VolcanoPlanner,有关此算法的具体内容可以参考原码
- 如何使用Calcite
由于Calcite是Java语言编写,因此只需要在工程或项目中引入相应的Jar包即可,下面为一个可以运行的例子:
|
|
类Triple 对应的表定义:
Calcite 其它方面
Calcite的功能远不止以上介绍,除了标准SQL的,还支持以下内容:
对流相对概念支持,如在SQL层面支持Window概念,如Session Window, Hopping Window等。
支持物化视图等复杂概念。
独立于编程语言和数据源,可以支持不同的前端和后端。
值得一提的是,Calcite支持异构数据源查询,比如数据存在es和mysql,可以通过写sql join之类的操作,
让calcite分别先从不同的数据源查询数据,然后再在内存里进行合并计算;
另外,它本身提供了许多优化规则,也支持我们自定义优化规则,来优化整个查询。
总结
以上内容主要介绍上Calcite相关概念并通过相例子说明了Calcite使用方法, 希望通过上述内容,读者能对Calcite有初步的了解。
由于笔者使用和探索Calcite时间也不长,以上内容难免有错误与不准确之处,还望各位读者不吝指正,相互学习。
Reference
https://www.jianshu.com/p/2dfbd71b7f0f
https://www.infoq.cn/article/new-big-data-hadoop-query-engine-apache-calcite/