Kylin术语
维度(Dimension)
一组属性,提供结构化的标签信息,一般作为报表的坐标轴。度量(Measure)
一类可以进行聚合分析的特殊维度,聚合后的结果称为指标。事实表(Fact Table)
数据仓库中的中央表,用于描述业务内特定事件的数据。维度表(Lookup Table)
维度属性的集合,人们观察数据的特定角度。基度(Cardinality)
指数据表中某一列数据去重后的元素个数。星型模型(Star Schema)
一种多维的数据关系,由一张事实表和一组维度表组成。cube
一个cube就是一个Hive表的数据按照指定维度与指标计算出的所有组合结果。cuboid
某一维度组合下,度量聚合后的结果集合。有个特殊的cuboid叫 base cuboid,比如维度有ABCD,(A,B,C,D)称为Base cuboid数据立方体(cube)
一组用于分析数据的相关度量值和维度,是所有cuboid的集合,作为存储和分析的基本单位segment
Cube Segment 是指针对源数据中的某一个片段,计算出来的 Cube 数据。
通常数据仓库中的数据数量会随着时间的增长而增长,而 Cube Segment 也是按时间顺序来构建的。衍生维度
维度表上的某一列通过PK可推的,换句话是可查询到的 比如由身份证可以推导性别,所以能通过PK推导的维度都可以设置为衍生维度。
衍生维度是放在snapshot中
Kylin核心技术:Cube与计算
比如我们有10多亿中国人口数据,要统计男女比例这么个需求。如果直接从硬盘里提取数据来统计肯定会很慢,磁盘速度大概是几百兆/秒。
即使把数据放到内存中也最多提升100倍的速度。
所以,可以用与计算来统计男女比例
维度表和事实表
我学到了一个数据仓库的概念,维度表(Fact Table)和事实表(Lookup Table)。
通过下面例子就让我明白了:
学过数据库的童鞋应该都知道星型模型,星型模型在数据仓库的设计中可以为是一种典型的维度模型。
我们在进行维度建模的时候会建一张事实表,这个事实表就是星型模型的中心,然后会有一堆维度表,这些维度表就是向外发散的星星。
那么什么是事实表、什么又是维度表吗,下面会专门来解释。
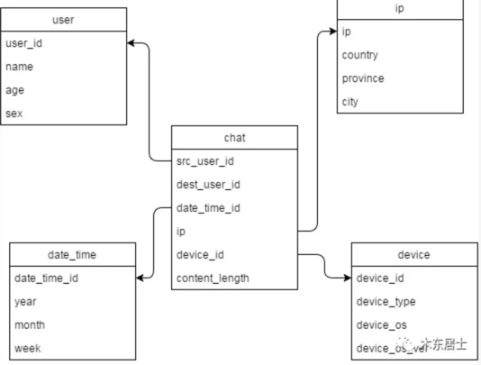
中间的chat表就是事实表。其它周边的表就是维度表。
维度设计
只有普通维度会影响Cuboid的数量和存储膨胀率,衍生维度并不参与Cuboid计算,而是有衍生维度对应的外键FK参与计算Cuboid。
在查询时,对衍生维度的查询会首先转换为对外键所在维度的查询,因此会牺牲少量查询性能。
Kylin暂时不支持星座模型
默认情况下,系统将会为所有的维度表创建快照。
设计新的模型,将大维度表改为事实表
设计规则如下:
经常出现在规律条件中的维度应当设为普通维度,以达到更好的查询性能。
Derived 衍生类型的前提是要放到快照表里的
- For normal dimensions, Kyligence has max number restriction of 62
- If a dimension table is used in cube design, its corresponding fact table foreign key will be added as normal dimension even it’s not used.
维度优化
Mandatory Dimension: 一定group by的字段
Hierarchy Dimension: 国家、省、市
Joint Dimension: 要么一起出现,要么不出现,比如:A、B、C绑在了一起 (很少有这样的场景)
Rowkey
UHC不要用Dict作为encoding;
常用的字段比如日期字段要放在Rowkey的前面
高基维放置在低基维前面
过滤的维度放置在非过滤前面
max length of FixedLength(N) for UHC of varchar/char type will be 256
Cube Build
Supported Cube Build Types:
尽量使用增量加载
计划合并你的增量segment
用增量加载的时候要考虑下SCD
星型模型和雪花模型
fact table 外围一圈 dimension table 就是星型模型
dimension table 外再围一圈 dimension table就是雪花模型
System Configuration
Important configurations:
Job retry
Pushdown:对于没有cube能查得结果的sql,Kylin支持将这类查询通过JDBC下压至备用查询引擎如Hive, SparkSQL, Impala等来查得结果
Query cache(process level/shared)
Compression
Configuration override
System
Project
Cube
Authorization Management
project: Query, Operation , Managment, Admin
table: Table query, Row query, Column query
Caution: column ACL is a blacklist.
Resource Isolation
KE can submit cube build jobs to specified Yarn queues per: system level;project level;cube level
应用发布流程
DEV -> QA ->(sign off) PROD
Daily Operation
Garbage cleanup
e.g.: segment merged, cube purgedSystem upgrade
Minor version upgrade
Major version upgradeSystem backup/restore
System level
Project level
Rest API
Authorization 这个Header的内容是 “ADMIN:yourpassword”的base64 encode
Hadoop生态和和MPP数据库的区别
Hadoop跟MPP的存储模型不一样。
Hadoop生态的存储用HDFS,HDFS的扩展是通过元数据来做的,它有中心节点用来存元数据,在加入新的节点的时候,
只需要修改元数据就可以,所以HDFS可扩展能力是收到管理元数据那台机器的性能限制的。一般来说可以到10K这个
规模,再向上就不行了。
而MPP要自己做切分,自己做切分就带来动态调整的问题。MPP通常采用的是没有中心节点的存储模式,比如hash,
每增加节点的时候,都需要rehash,这样当规模到了几百台的时候,扩展能力就下来了。
Hive在内存管理上方式不大一样。
MPP内存管理比较精细,他主要的想法是在每个机器上放个数据库,传统数据库的内存管理比较复杂,主要是内外存
交互的东西,这样的架构决定了MPP在小数据量的时候,latency可以做的比较小,但是数据量大的时候,
throughput做不上去了。
而Hive的内存管理非常粗放,它后来就是MapReduce的job,MR的job是没有太多精细的内存管理,就是拼命地
scan,完了就是spill,这样的架构导致throughput很大,但是latency很高。
failover机制,
Hive的failover就是MR的failover,job挂掉了重新换机器跑就完了。
MPP它的计算是要attach到数据节点上去的,如果你规模上去,那么fail的可能性就上去了,这样如果你每次计算
都有台机器挂了,一挂,别人就要等你,而不是换台机器继续跑。可以用木桶效应类比。
Cube设计
Rowkey的具体格式是cuboid id + 具体的维度值(最新的Rowkey中为了并发查询还加入了ShardKey)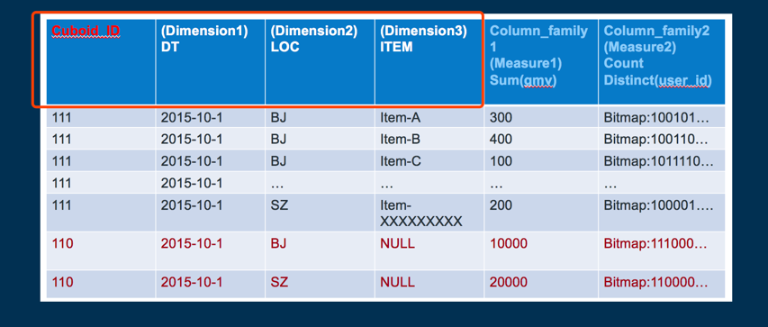
前面4个框着的作为Rowkey,比如,2015-10-1的维度序号为1,BJ的序号为0,item-A序号为0,则最终Rowkey为 111+100
Rowkey的设计原则:
- 结合业务场景特点,按照查询频次来放置字段顺序
- 通过设计的Rowkey尽可能的将数据打散到整个集群中,负载均衡
- 设计的Rowkey尽量简短
有3个方面要考虑:
Encoding
我们的编码方式能够大大减少每行Cube数据的体积。
而Cube中可能存在数以亿计的行数,使用编码节约的空间累加起来将是一个非常巨大的数字。排序
高概率用于过滤的列
基数高的列(用它进行过滤时,返回的结果集小)
排序评分=过滤概率*过滤强度
经常使用到的维度提前—在需要进行后聚合的场景中效率会更高。分片
按维度分片(Shard by Dimension)提供了一种更加高效的分片策略,那就是按照某个特定维度进行分片。
简单地说,如果Cuboid中某两个行的Shard by Dimension的值相同,
那么无论这个Cuboid最终会被划分成多少个分片,这两行数据必然会被分配到同一个分片中。
Shard by维度要求
仅支持单一维度
基数足够高(几十万)
分布均匀
经常进行group by和filter
更多的优化原理要参考Rowkey的设计