在学习《算法》一书中了解到:
优先队列是一种抽象的数据类型,优先队列最重要的操作就是删除最大元素和插入元素。
实现优先队列可以用数组,链表,最好的方式还是用堆。
我们可以把任意优先队列变成一种排序方法。将所有元素插入一个查找最小化元素的优先队列,然后再重复调用删除最小元素的操作将它们按顺序删去。用无序数组实现的优先队列这么做相当于进行一次选择排序。用基于堆得优先队列这样做等同于堆排序!
要了解堆首先得了解一下二叉树,在计算机科学中,二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
二叉树又分为满二叉树(full binary tree) 和 完全二叉树(complete binary tree)
满二叉树:一棵深度为 k,且有 2k - 1 个节点称之为满二叉树
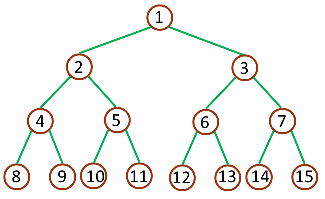
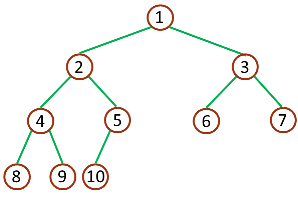
完全二叉树则满足序号和满二叉树的完全对应。
如下图,是一个堆和数组的相互关系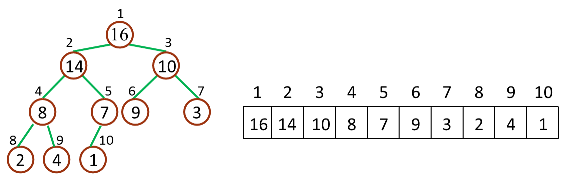
对于给定的某个结点的下标 i,可以很容易的计算出这个结点的父结点、孩子结点的下标:
- Parent(i) = floor(i/2),i 的父节点下标
- Left(i) = 2i,i 的左子节点下标
- Right(i) = 2i + 1,i 的右子节点下标
堆排序原理
堆排序就是把最大堆堆顶的最大数取出,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出,这个过程持续到剩余数只有一个时结束。在堆中定义以下几种操作:
最大堆调整(Max-Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点(左子树不一定大于右子树)
创建最大堆(Build-Max-Heap):将堆所有数据重新排序,使其成为最大堆
堆排序(Heap-Sort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
继续进行下面的讨论前,需要注意的一个问题是:数组都是 Zero-Based,这就意味着我们的堆数据结构模型要发生改变
相应的,几个计算公式也要作出相应调整:
Parent(i) = floor((i-1)/2),i 的父节点下标
Left(i) = 2i + 1,i 的左子节点下标
Right(i) = 2(i + 1),i 的右子节点下标
最大堆调整(MAX‐HEAPIFY)的作用是保持最大堆的性质,是创建最大堆的核心子程序,作用过程如图所示:
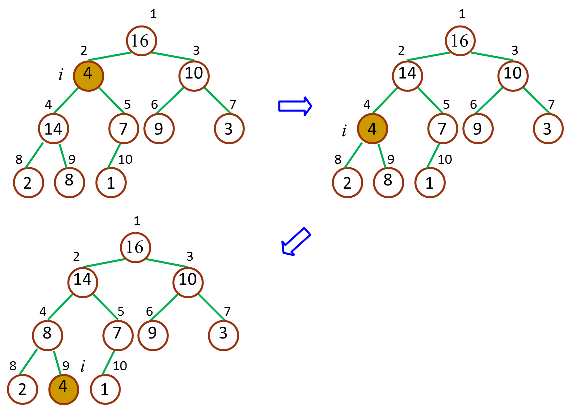
源码如下:
|
|