说说Spark 的宽依赖和窄依赖
前言
众所周知,在Spark中可以对RDD进行多种转换,父RDD转换之后会得到子RDD,于是便可以说子RDD的诞生需要依赖父RDD。在Spark中一共有两种依赖方式,分别是宽依赖和窄依赖。
rdd 的 toDebugString 可以查看RDD的谱系
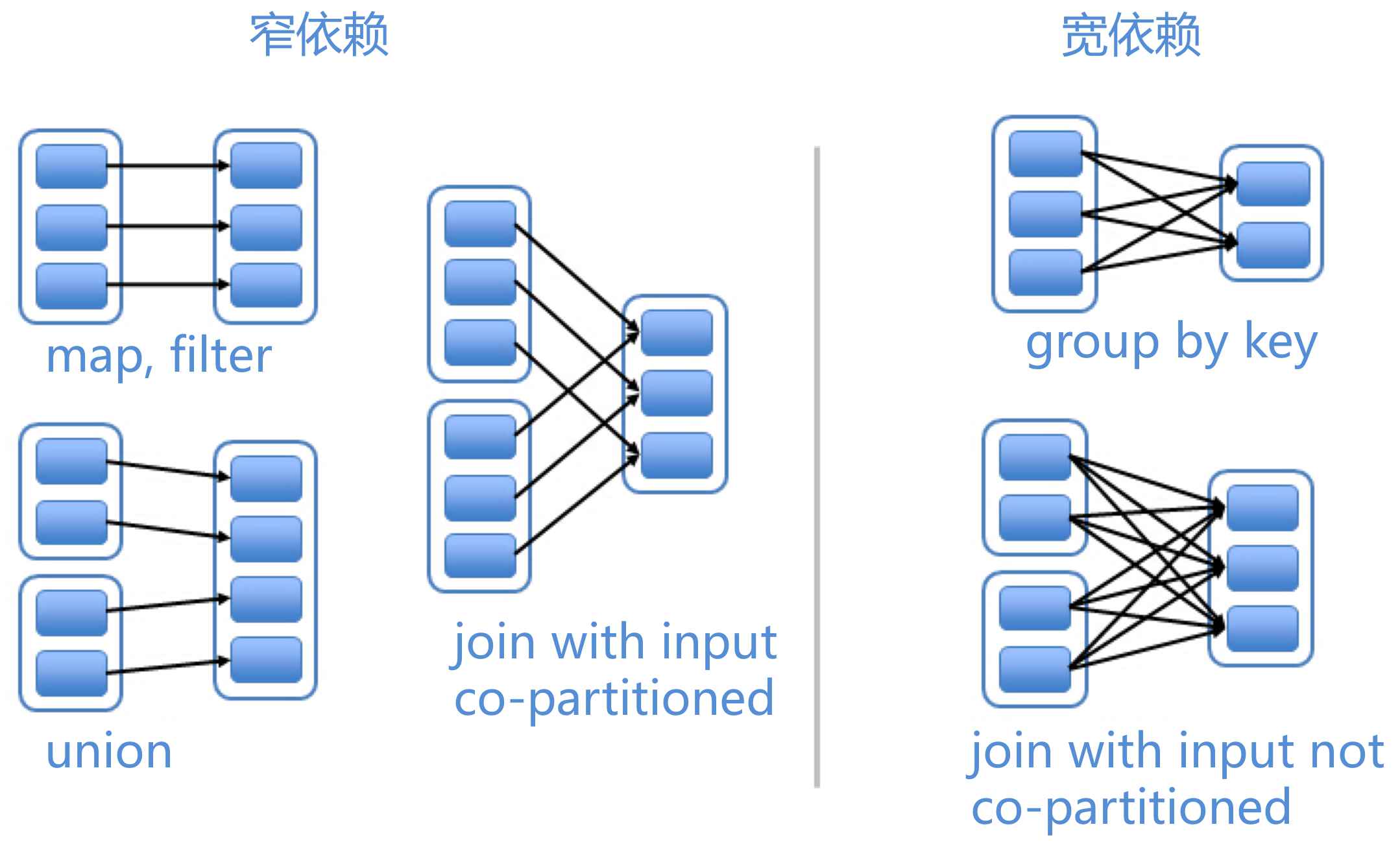
窄依赖
如果父RDD的每个分区至多只对应一个子RDD的分区,则这种依赖关系称为窄依赖。
常见的窄依赖算子有:map、filter、union。
对窄依赖RDD进行Lineage恢复时,如果子RDD某个分区坏了,通过父RDD指定分区重算时,将不会重算其他正常的分区,避免了冗余计算,提高了性能。
宽依赖
如果父RDD中至少有一个分区对应子RDD的多个分区(至少两个分区),则这种依赖关系称为宽依赖。
常见的宽依赖算子有:groupByKey、sortByKey。
对宽依赖RDD进行Lineage恢复时,如果子RDD某个分区坏了,通过父RDD指定分区重算时,有可能会重算一些其他正常的分区,会有冗余计算,性能开销也会比窄依赖大很多。
宽依赖通常是Spark拆分Stage的边界,在同一个Stage内均为窄依赖。
总结
我们可以不用去背宽窄依赖的概念和对应关系之类的。我们应该知道为什么要区分宽窄依赖,它的目的是什么。其实目的就是提醒我们尽量地使用窄依赖,因为这样会减少风险,
当子RDD的某个partition损坏的时候是否要重新计算很多父RDD的多个partition呢。这个才是宽窄依赖的重点。
另一个划分看宽窄依赖的目的是:划分stage。至于划分stage的目的,就是要等待其它节点的所有partition全部计算完成才能作下一个阶段的计算。
在网上查了很多资料貌似有很多不同的定义。在看了很多解释后了解到,依赖的问题在论文里和在Spark的实现中的定义是不一样的。
在论文中,是叫narrow dependency和wide dependency。
如果父RDD的每个partition只被子RDD的一个partition所依赖,就叫Narrow dependency,否则叫Wide dependency。在Spark中,是叫narrow dependency(也叫完全依赖)和shuffle dependency(也叫部分依赖)。
如果父RDD的每个partition(并且是partition里的部分数据)都被子RDD的每个partition所依赖才叫ShuffleDependency,其余情况都是NarrowDependency。
SparkInternals dependency图解
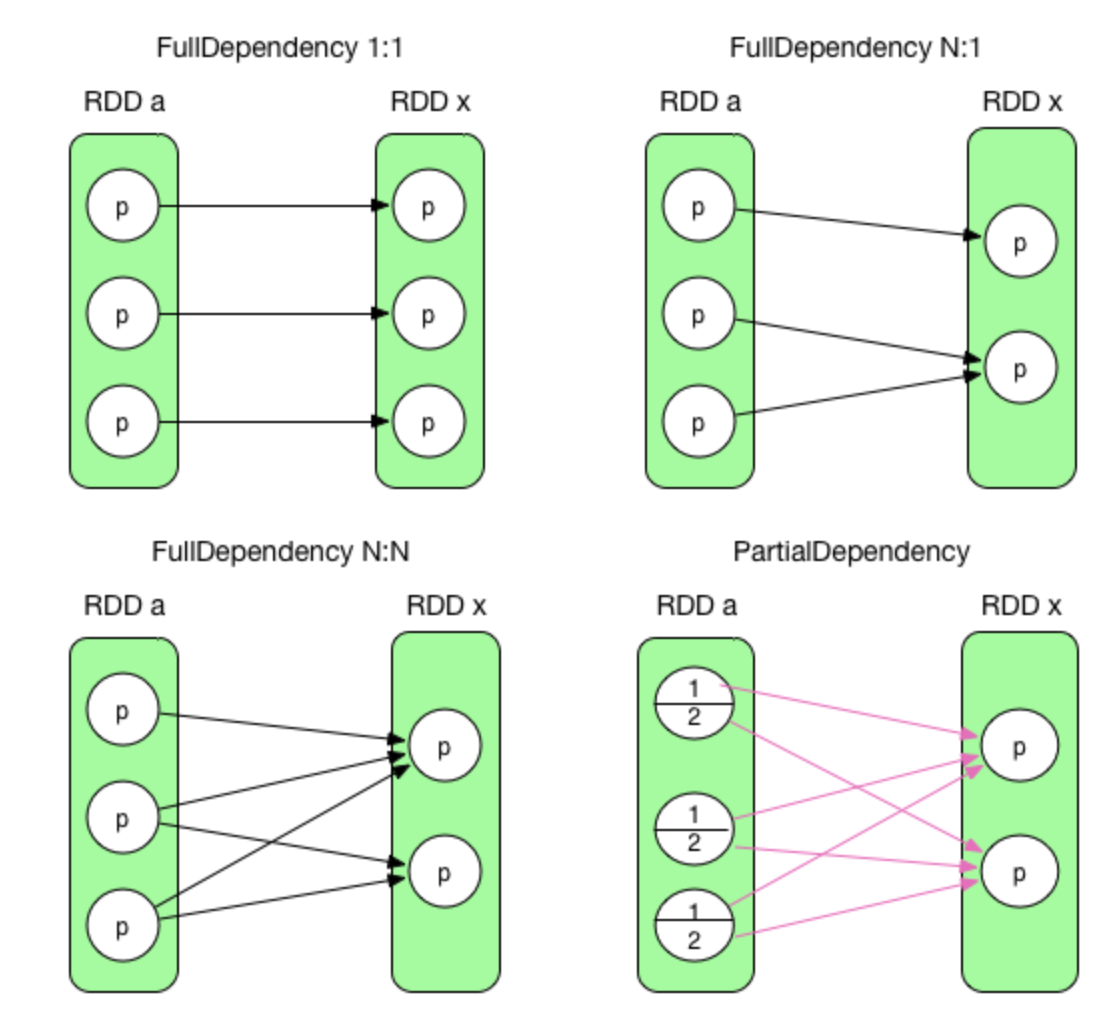
前三个是完全依赖,RDD x 中的 partition 与 parent RDD 中的 partition/partitions 完全相关。最后一个是部分依赖,RDD x 中的 partition 只与 parent RDD 中的 partition 一部分数据相关,另一部分数据与 RDD x 中的其他 partition 相关。
在 Spark 中,完全依赖被称为 NarrowDependency,部分依赖被称为 ShuffleDependency。其实 ShuffleDependency 跟 MapReduce 中 shuffle 的数据依赖相同(mapper 将其 output 进行 partition,然后每个 reducer 会将所有 mapper 输出中属于自己的 partition 通过 HTTP fetch 得到)。
- 第一种 1:1 的情况被称为 OneToOneDependency。
- 第二种 N:1 的情况被称为 N:1 NarrowDependency。
- 第三种 N:N 的情况被称为 N:N NarrowDependency。不属于前两种情况的完全依赖都属于这个类别。
- 第四种被称为 ShuffleDependency。
N:N NarrowDependency 的几个很经典的情况是:coalesce 和 cartesian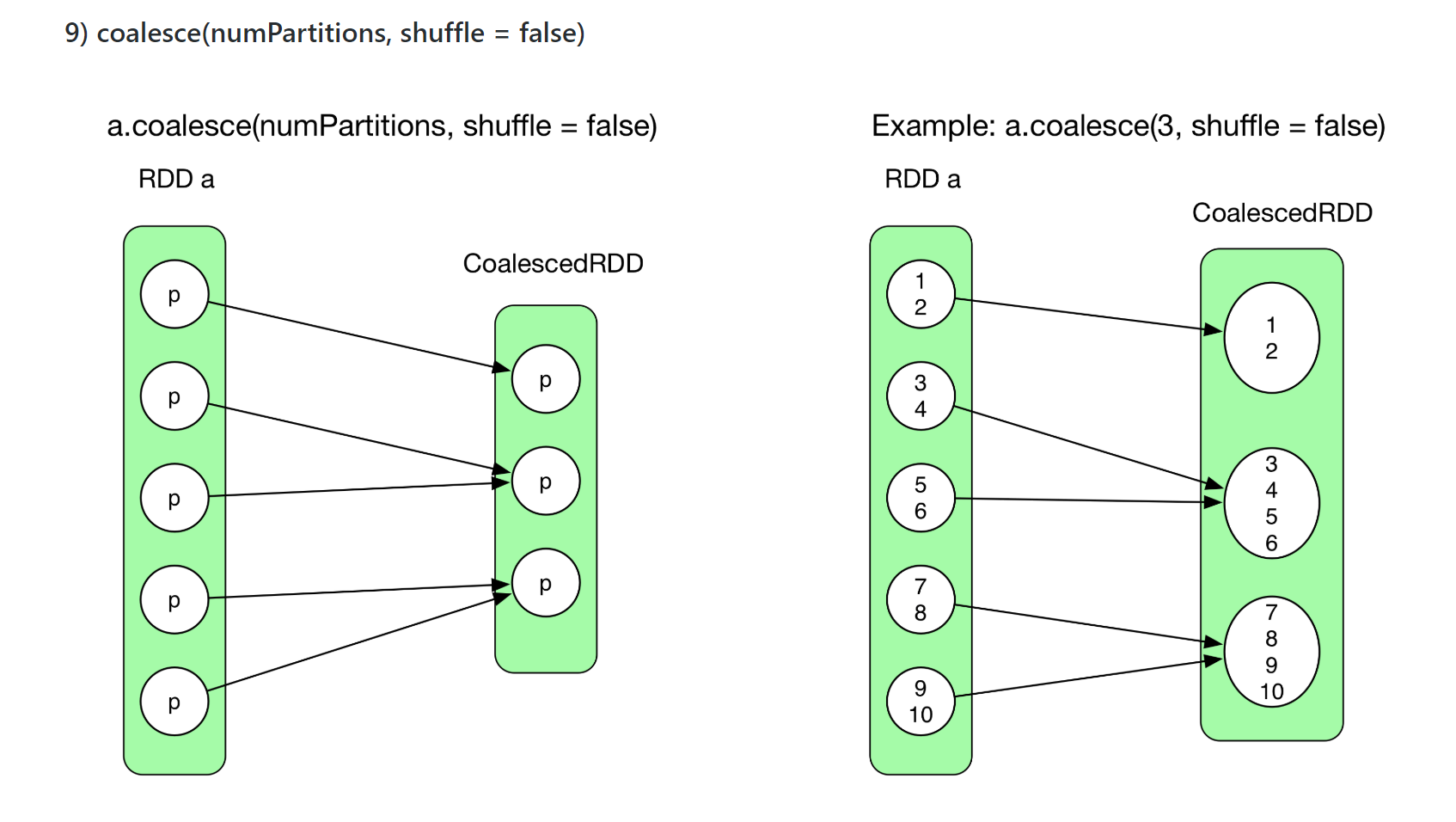
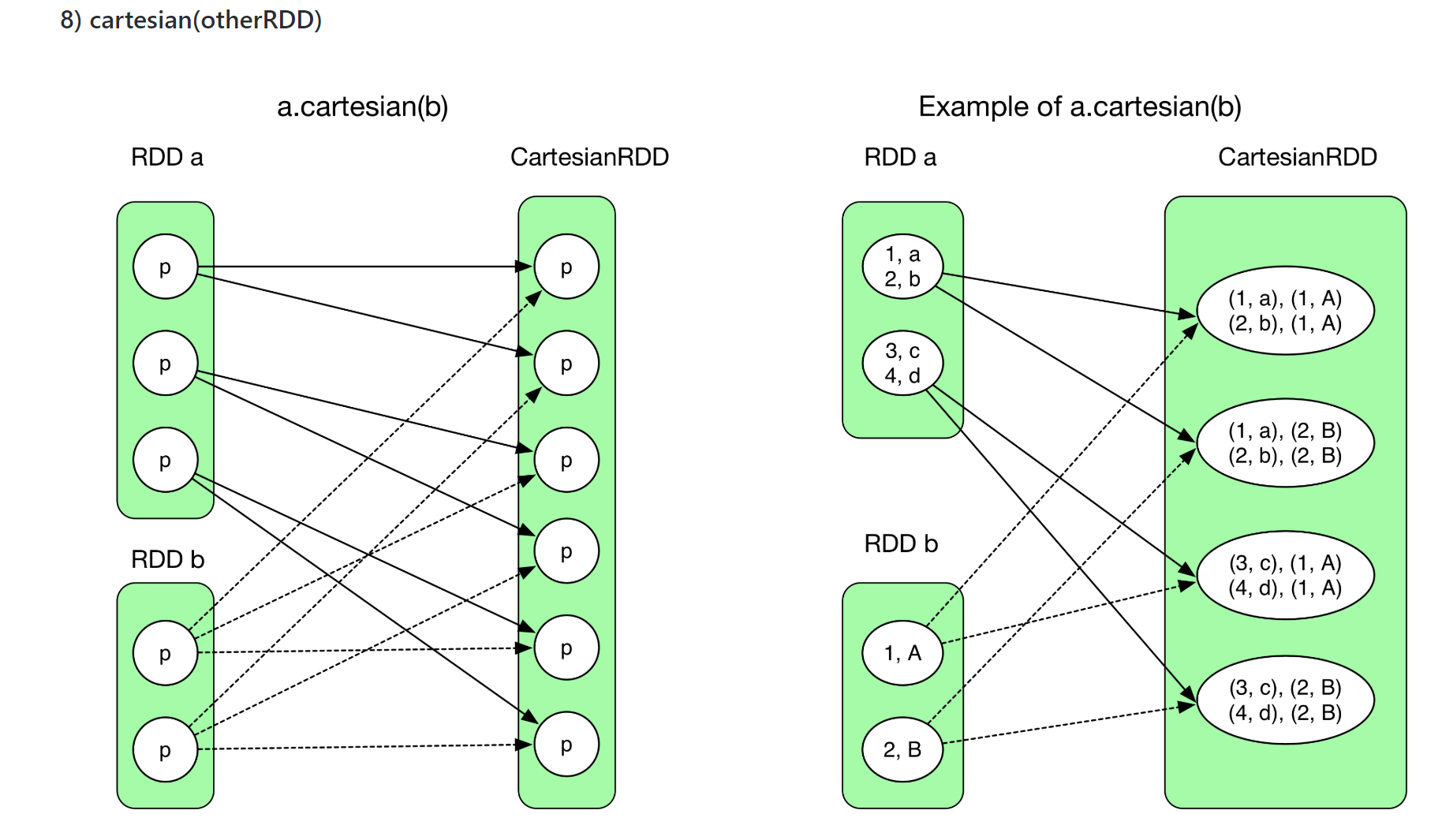
以上两种情况它们仍然可以在一个stage里的pipeline以一个task计算。不用等所有的task计算完再计算。因为它不是shuffle操作。
Reference
https://github.com/JerryLead/SparkInternals/blob/master/markdown/2-JobLogicalPlan.md
https://www.zhihu.com/question/37137360/answer/715150822